ACMG class 를 수치로 표현하는 방법 - bayesian score
안녕하세요. 한헌종입니다.
오늘은 지난번에 이어, ACMG pathogenicity class 의 수치적 표현에 대한 이야기를 하려 합니다.
글 맨 아래에는 ACMG evidence 조합에 따라 class 와 bayesian score를 구할 수 있는 계산기를 만들어 보았으니 한번 참고해보세요!
아래 내용은 다음 논문을 참조해서 작성했습니다:
Tavtigian, Sean V et al. “Modeling the ACMG/AMP variant classification guidelines as a Bayesian classification framework.” Genetics in medicine : official journal of the American College of Medical Genetics vol. 20,9 (2018): 1054-1060. doi:10.1038/gim.2017.210
ACMG class 가 뭐더라
지난번에 말씀드린 대로, ACMG/AMP guideline에 따라 각 유전변이의 pathogenicity를 판별할 수 있습니다.
규칙에 따라 여러 evidence를 할당하고, 그 결과를 조합해 5가지 class 중 하나를 규정하는 방식이죠.
5가지 class는 다음과 같습니다: Pathogenic, Likely pathogenic, vairiant of uncertain significance, Likely benign, Benign.
이를 줄여서 P, LP, VUS, LB, B 로 간단히 나타내기도 합니다.
ACMG guideline을 따르면 pathogenicity를 어느정도 가늠할 수 있게 됩니다.
그러나 연구자들은 이를 ‘수치적’으로 나타내기를 원했습니다.
이를 위해 연구자들은 Bayesian framework 를 사용해 수치화 하는 방법을 강구해냅니다.
바로 다음 식처럼 말이죠.
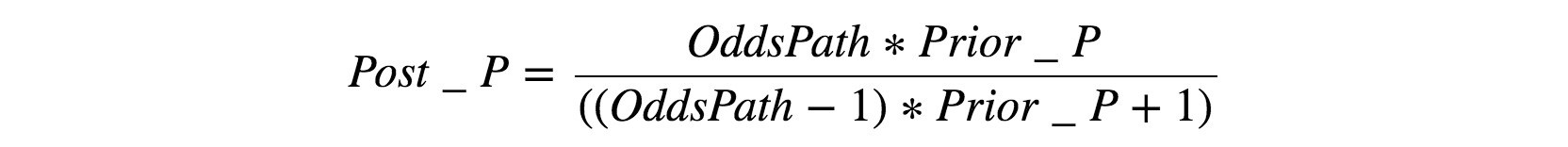 |
Bayesian framework에 따라서, 먼저 알고 있는 prior probability를 여러 조건부확률을 사용해 posterior probability를 계산하는 방식입니다.
이 식을 사용하면 특정 변이의 pathogenicity를 0~1 사이의 값으로 나타낼 수 있게 됩니다.
물론, 결국엔 ACMG guideline 조합에 따른 5가지 class를 사용해서 변이를 설명해야 합니다.
어떻게 계산하는 건가요?
그럼 식에 대해 좀더 알아보겠습니다.
위의 공식은 밑에 있는 일반적인 베이즈 규칙에 따라 만들어졌습니다:
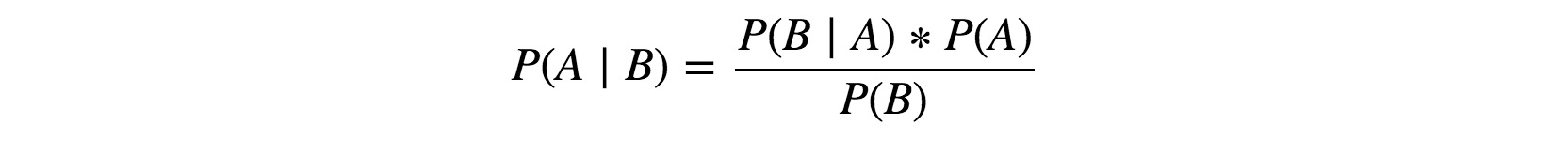 |
여기서 P(A) 가 prior probability, 즉 the probability of pathogenicity 가 됩니다.
변이가 병원성을 가질 확률이죠.
P(B)는 the probability of the evidence for pathogenicity 입니다.
P(A|B) 가 여기서 posterior probability 가 되는데요,
그 의미는 the probability of pathogenicity given the evidence 즉 주어진 evidence들에 대해 이 변이가 병원성을 가질 확률입니다.
P(B|A) 는 the probability of the evidence, given that the variant is pathogenic, 즉 pathogenic 변이가 주어졌을 때 각 evidence를 가질 확률입니다.
여기서 prior는 0.1을 기본값으로 사용합니다.
이는 논문에서 제시한 값으로써, 유전자 패널 등에서 병원성 변이를 발견하게 될 확률을 경험적으로 나타낸 것이라고 하는군요.
Odds_Path 는 어떻게 구하는거죠?
Odds_Path 는 odds of pathogenicity 를 나타냅니다.
이는 evidence categories 들을 설명하는 방향으로 만들어졌습니다.
그래서 이 값이 1 보다 크면 pathogenic evidence가 많다는 것이고, 1보다 작으면 benign evidence 가 많다는 것을 의미입니다.
이 Odds_Path 는 다음 식으로 구해집니다:
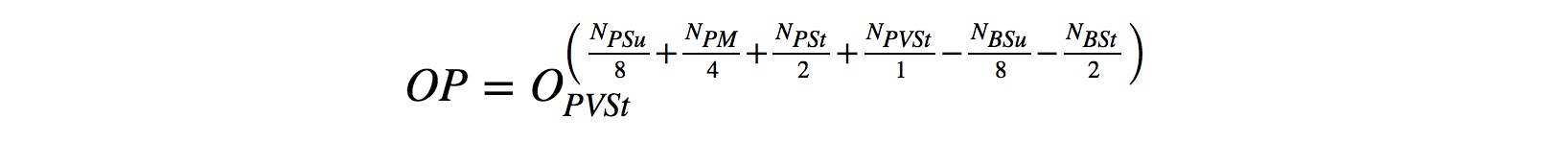 |
설명드리자면, Odds_Path 는 PVS evidence 의 odds 값을 ‘특정 값’으로 제곱해서 계산합니다.
그 ‘특정 값’ 은 각 evidence 의 개수를 활용해 만들어집니다.
예를 들어, NPSu 는 pathogenic-supporting evidence의 개수를 말합니다.
이 evidence의 개수는 그 strength에 따라서 2배씩 줄어들도록 보정이 되는데요,
그 결과 very strong evidence 한개의 영향력은 strong evidence 두 개의 영향력과 같게 됩니다.
(여기서의 그 ‘두 배’ 라는 값도 역시 논문에서 정해준 값입니다.)
또한 pathogenic evidence 개수는 덧셈, benign evidence는 뺄셈으로 사용해서 결과값을 보정하고 있습니다.
Benign evidence 가 많으면 odds_path 가 1 이하로 떨어지겠죠?
여기서, O(PVSt) 즉 the odds of very strong pathogenicity 는 논문에서 350으로 제시하고 있습니다.
이렇게 해서 Odds_path 를 구하는 방식을 알아보았습니다.
그럼 이 값이 뭘 뜻하나요?
결국 Bayesian score를 구하기 위해서는 다음 두 단계를 거치면 됩니다.
- Odds_Path 를 evidence 개수를 사용해 구한다.
- Posterior probability를 bayesian framework에 따라 계산한다.
여기서 제시한 O(PVSt)=350, Prior=0.1 를 사용하면 다음과 같은 현상이 나타납니다:
- Post_P >= 0.99 : Pathogenic
- 0.99 > Post_P >= 0.90 : Likely pathogenic
- 0.90 > Post_P > 0.1 : VUS
- 0.1 >= Post_P > 0.001 : Likely benign
- 0.001 >= Post_P : Benign
즉 Bayesian score 가 pathogenicity를 나타낼 수 있게 된 거죠.
높을 수록 Pathogenic 변이이며, 특정 값을 넘는지를 통해 class 도 알 수 있습니다.
그러나 이 공식으로 구해진 bayesian score는 완벽하지 않아서, 여러 예외상황이 발생하기도 합니다.
예를 들어 class 는 VUS 로 분류되지만 bayesian score 는 0.9를 넘는 경우가 발생하기도 하죠.
bayesian score는 설명을 돕기 위한 점수일 뿐이고, 결국 ACMG class 를 중점적으로 봐야한답니다.
ACMG class 계산기
js 를 사용해서 ACMG class 계산기를 만들어보았습니다.
해당하는 rule을 클릭해서 조합을 만들면, 밑부분의 결과에 ACMG class 와 bayesian score가 계산되어 나타납니다.
한번 직접 사용해보세요!
ACMG class calculator
made by HJHan
click rules below:
| PVS1 | ||||||
| PS1 | PS2 | PS3 | PS4 | |||
| PM1 | PM2 | PM3 | PM4 | PM5 | PM6 | |
| PP1 | PP2 | PP3 | PP4 | PP5 | ||
| BS1 | BS2 | BS3 | BS4 | |||
| BP1 | BP2 | BP3 | BP4 | BP5 | BP6 | BP7 |
| Reset | ||||||
| Class | Score | |||||
지금까지 ACMG class 를 수치화 하는 bayesian framework 를 살펴보았습니다.
더욱 자세한 내용은 맨 위에 말씀드린 논문에서 찾아볼 수 있습니다.
그럼 다음에 만나요!