원하는 시퀀싱 데이터 찾기 - GEO 검색 방법
안녕하세요 한헌종입니다.
오늘은 연구자들이 원하는 데이터를 찾고 싶을 때 가장 많이 검색하게 되는 GEO에 대해 설명하겠습니다.
GEO 는 Gene Expression Omnibus 의 약자입니다.
NCBI에서 운영하는 공개 유전체 데이터베이스죠.
몇몇 연구자분들은 논문을 제출할 때, 이곳에 데이터를 업로드해야 하는 일이 있으셨을 겁니다.
그만큼 많은 연구자들이 데이터를 업로드하고 사용하는 곳이 바로 GEO입니다.
GEO 만 잘 사용할 수 있어도, 원하는 데이터를 손쉽게 얻어서 다른 연구에 활용할 수 있습니다!
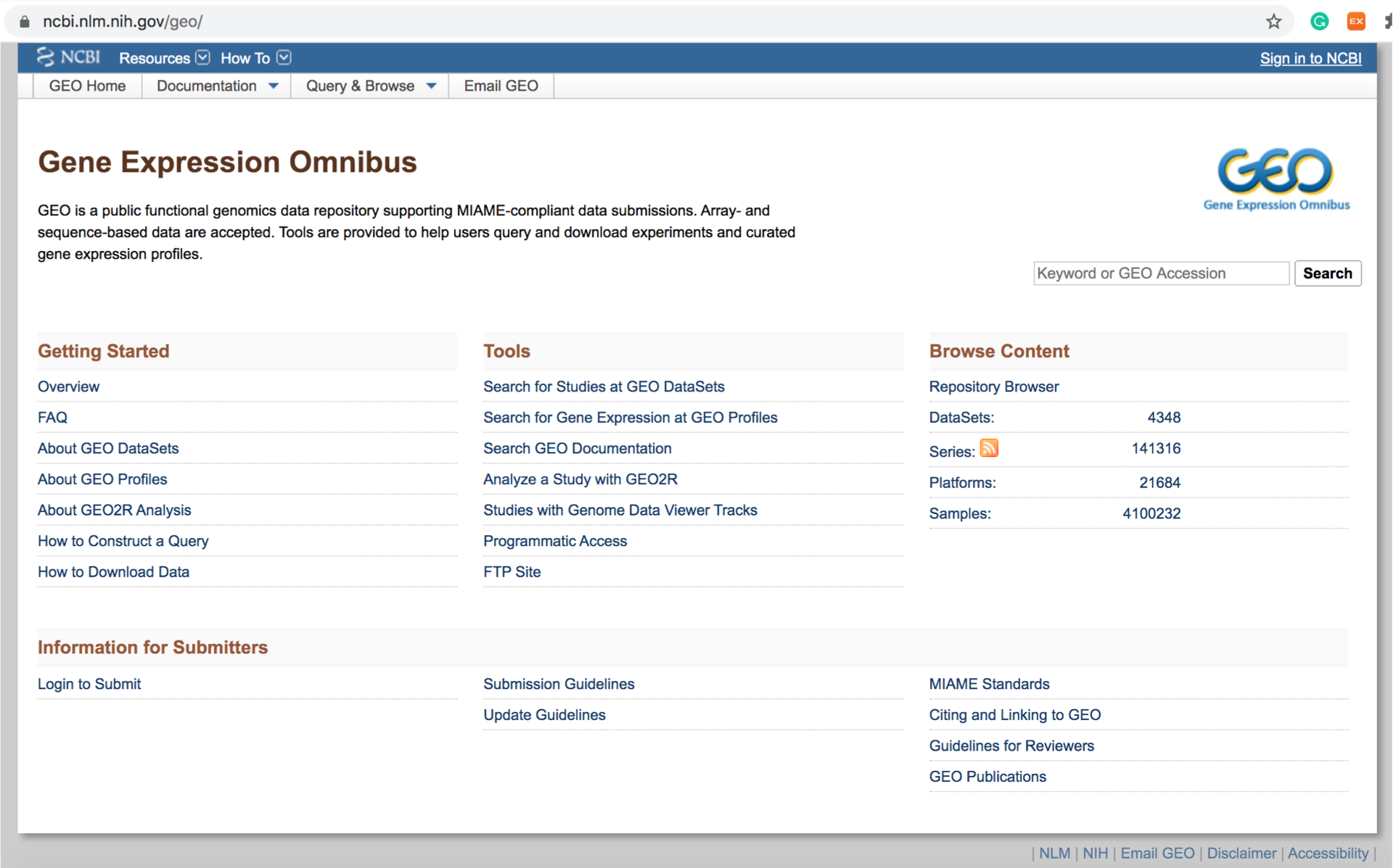 |
|---|
| GEO 홈페이지는 이렇게 생겼습니다. |
GEO 검색 전 알아둬야 할 3가지!
GEO 데이터는 크게 세 종류로 나눌 수 있습니다.
바로 GPL, GSE, GSM 이 그것입니다.
이 종류에 따라 데이터에 서로 다른 ID 가 부여되죠. (예를 들어 GSE12300 처럼 말이죠)
- GPL: Platform
GPL 은 유전체 데이터의 플랫폼을 이야기합니다.
microarray 실험의 경우, 사용된 Array chip 정보를 나타냅니다.
제품을 만든 회사 (Affymetrix, Agilent, Illumina) 정보 및 chip 의 상품명도 알 수 있습니다.
그러나, 더 중요한 것은 바로 chip 의 probe 정보입니다.
microarray 의 각 well 이 어떤 유전자의 probe 를 담고있는지 gene-probe mapping 정보를 제공하기 때문에, microarray 데이터를 분석하기 위해서는 꼭 GPL 정보가 필요합니다.
시퀀싱 데이터의 경우는 약간 다릅니다.
이 경우 플랫폼은 데이터를 만들 때 사용된 시퀀싱 기기를 알려줍니다.
예를 들어, Illumina NovaSeq 6000 인지 HiSeq X Ten 인지 등등을 알려주죠. - GSE: Series
GSE 는 하나의 데이터 시리즈를 말합니다.
즉 한 연구에서 나온 데이터라고 할 수 있죠.
예를 들어, 어떤 연구자가 여러 폐암 환자의 RNA-seq 데이터를 GEO에 업로드하게 된다면, 그 데이터들은 하나의 GSE ID 로 묶여지게 됩니다.
때문에 GSE 하나에는 해당 실험 디자인에 관한 정보 및 실험에 포함된 샘플들의 정보를 알 수 있죠.
아마도 여러분들은 GSE 중심으로 데이터를 검색하시게 될 겁니다. - GSM: Sample
GSM 은 샘플을 말합니다.
하나의 GSM ID 는 하나의 데이터를 나타내죠.
GSM 은 각 샘플의 세부 정보 및 개별 데이터를 포함하고 있습니다.
이 GSM 여러개가 묶인 것이 바로 GSE 가 되는 것입니다.
자, 이제 GPL-GSE-GSM 구조를 좀 알 수 있겠죠?
원하는 데이터를 GEO 에서 찾고 싶어요!
예를 들어 여러분이 난소암 환자의 RNA-seq 데이터를 찾고자 한다면 어떻게 찾아야 할까요?
아래 예제를 통해 보여드리겠습니다.
물론 GEO 홈페이지의 검색기능을 사용해도 됩니다만, GEO 의 검색기능은 구글처럼 뛰어나지 않습니다.
여기서는 그보다 더 효율적인 방법을 말씀드리겠습니다.
바로 GEO browser 를 사용하는 것입니다.
아래 그림처럼, GEO 홈페이지에서 Series browser 로 검색해 들어가 보세요.
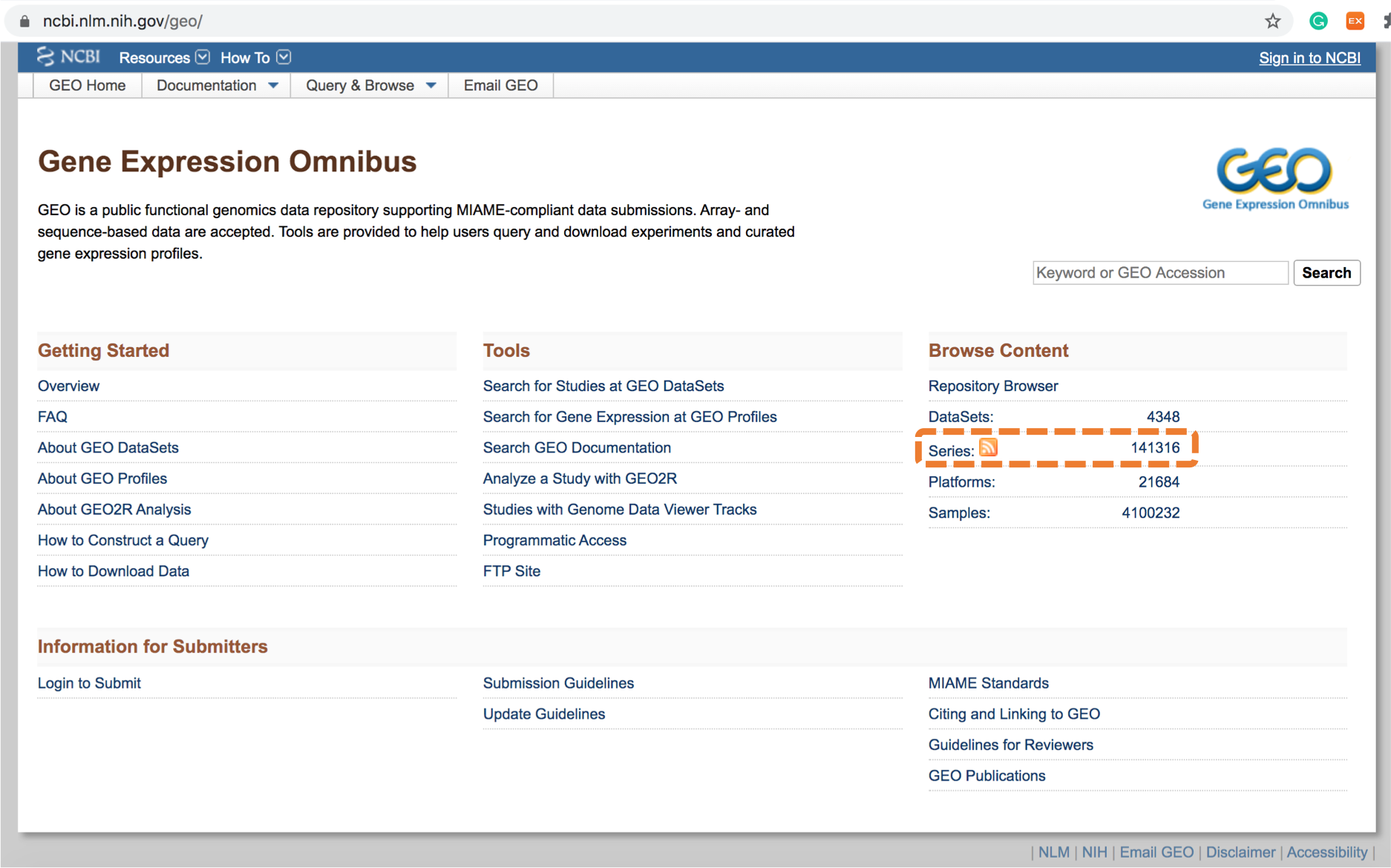 |
|---|
| 현재 GEO 에는 14만 개의 series 데이터가 있군요. |
이 부분을 클릭하면, GEO에 있는 모든 Series 정보가 다음 그림과 같이 나타납니다.
위에서 말씀 드렸듯이 각 series 는 각 연구별로 묶인 데이터 모음입니다.
GEO browser 에서는 이 series들의 title, series type 등을 구분해서 표 형태로 보여줍니다.
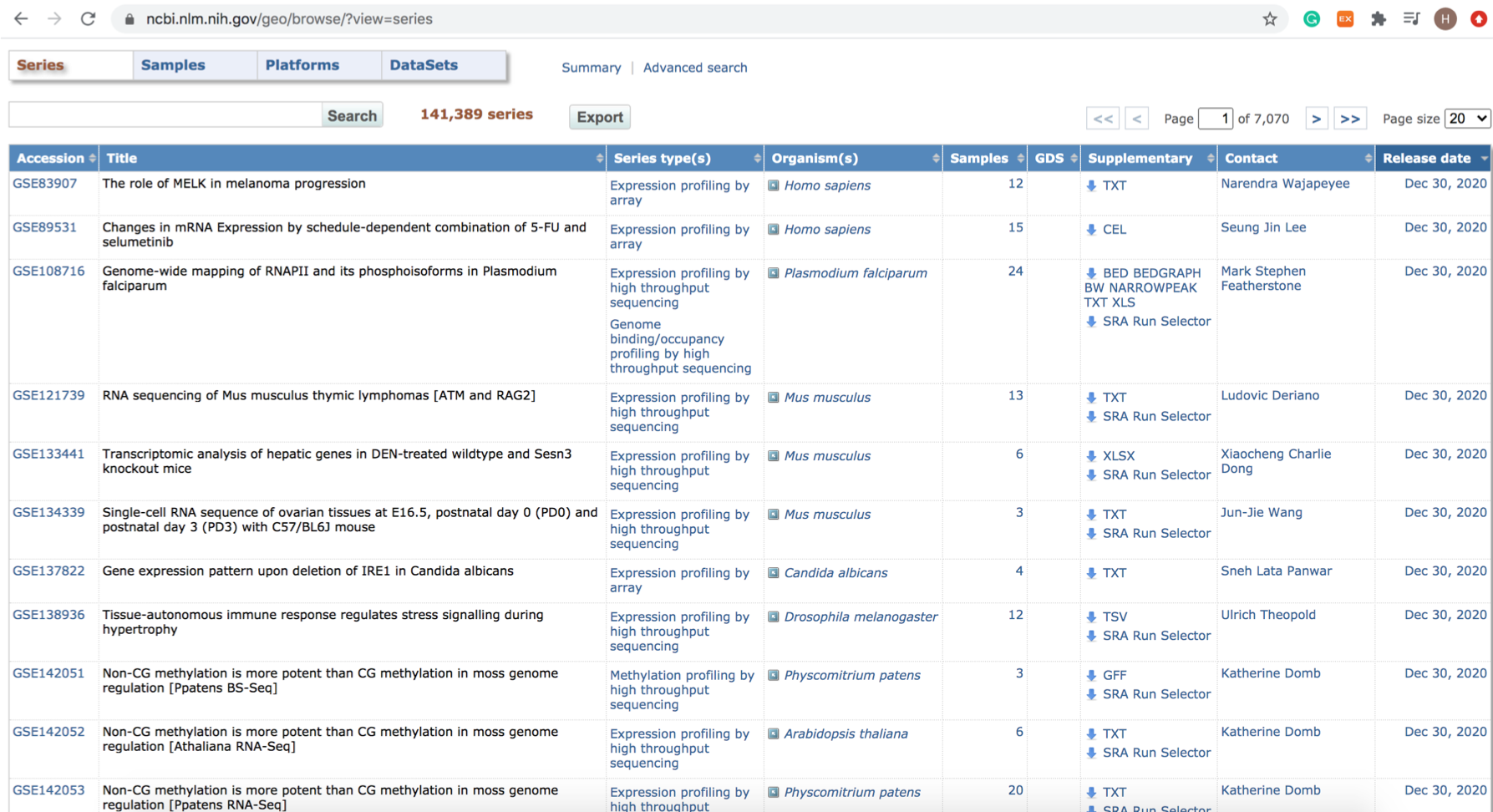 |
자, 그럼 난소암 환자의 RNA-seq 데이터 를 찾아볼까요?
표에 나타난 정보 중 원하는 종류가 있을 때, 이를 클릭하면 ‘필터’ 기능으로 해당 종류만 표에 남게 됩니다.
먼저 RNA-seq 데이터이므로 ‘Expression profiling by high throughput sequencing’ 데이터만 남겨볼까요?
표에서 ‘Expression profiling by high throughput sequencing’ 글자를 클릭해보세요.
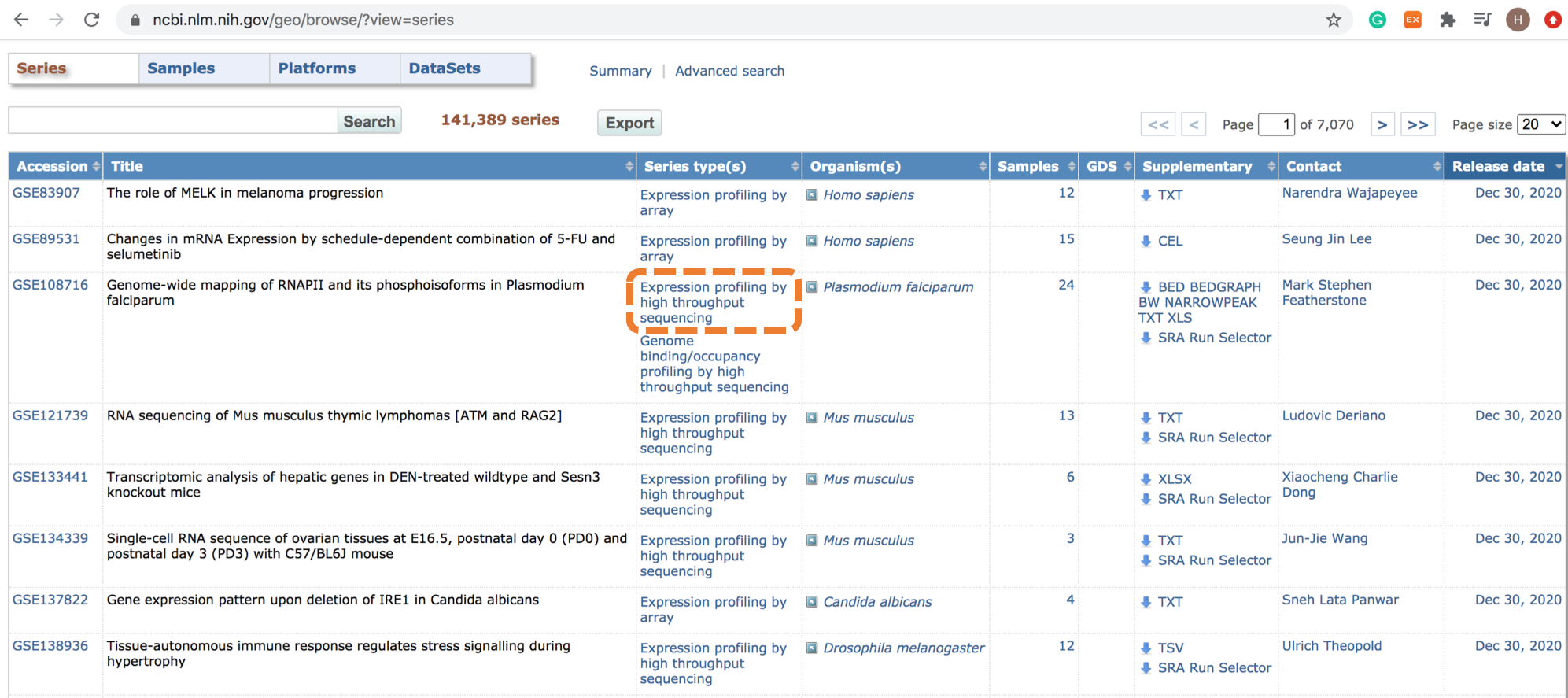 |
|---|
| 표에서 원하는 데이터 종류를 발견해 클릭하면 … |
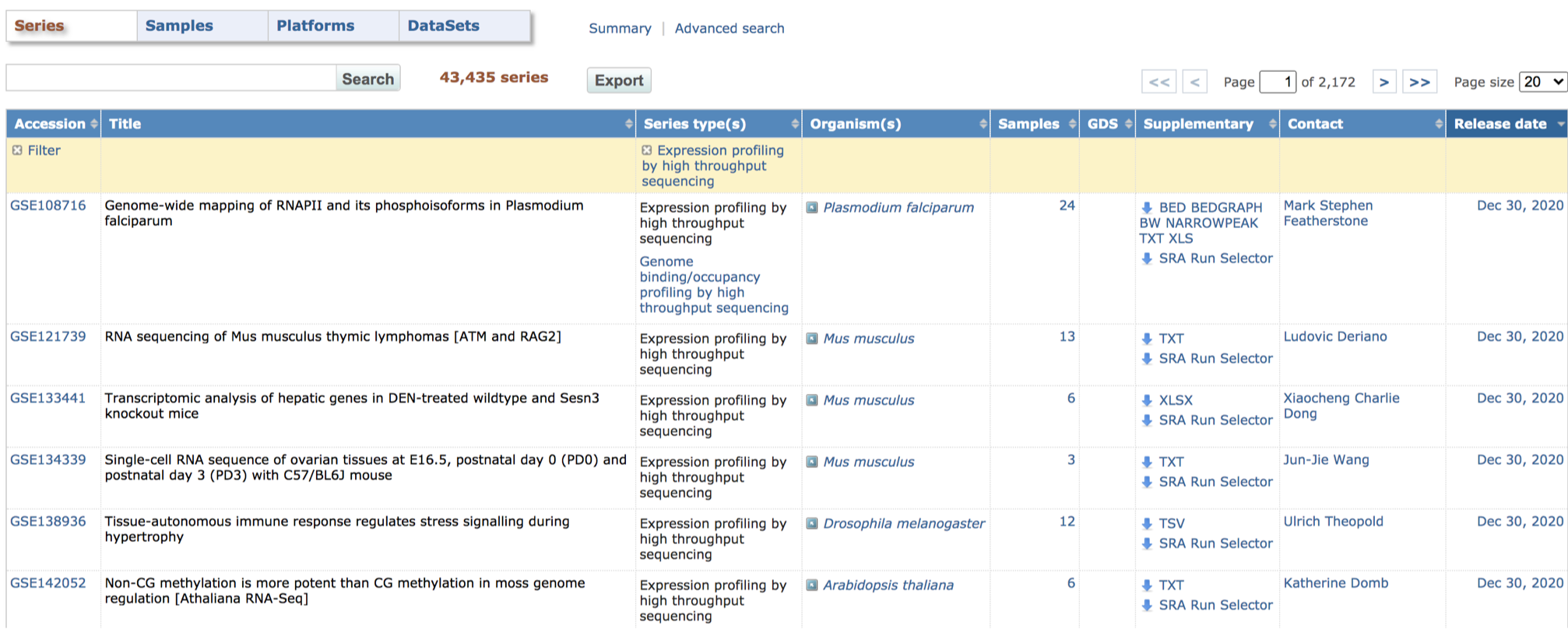 |
| 해당 종류의 데이터만 표에 남게 됩니다! |
기존에 14만개나 있었던 시리즈 데이터 중에, 우리가 원하는 RNA-seq 데이터는 약 4만개정도 있군요.
이런식으로 우리가 원하는 데이터를 좁혀나갈 수 있습니다.
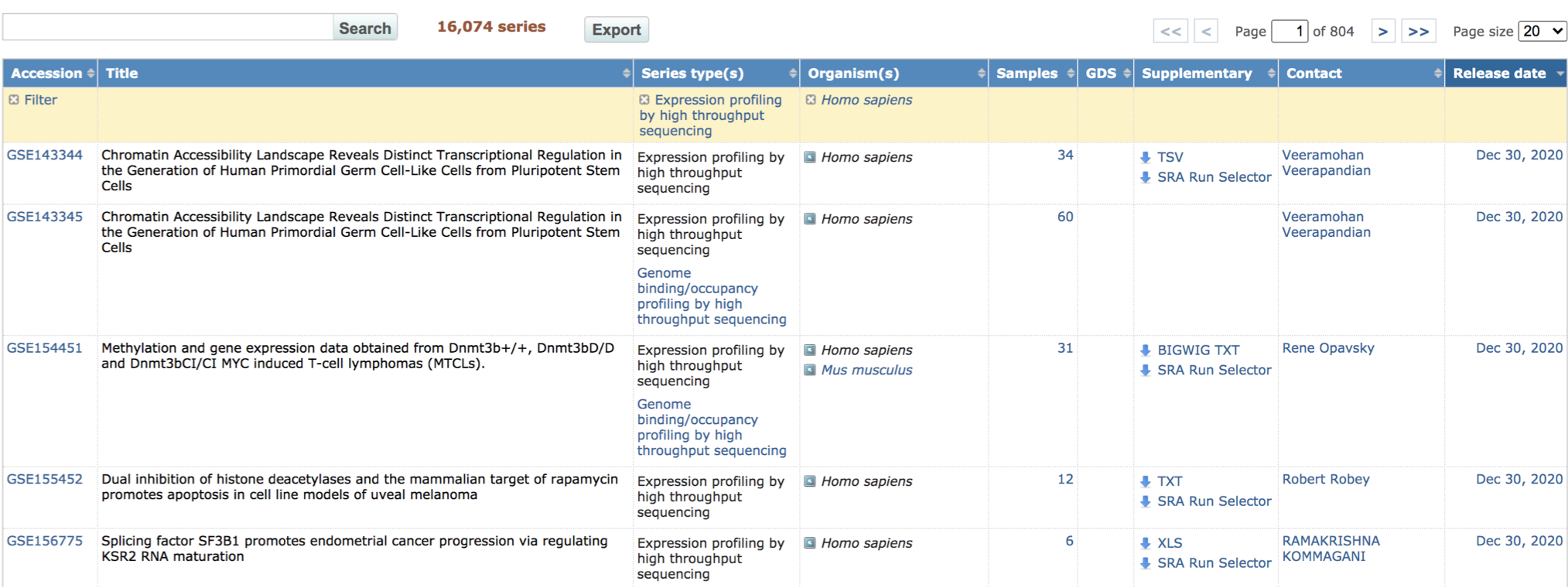
난소암 환자의 RNA-seq 데이터 를 찾아야 하므로 Homo sapiens 데이터만 남도록 필터링 해볼까요?
 |
자, 그럼 이제 검색 기능도 같이 활용해 봅시다.
왼쪽 위에 있는 검색 창에 원하는 검색어를 넣어보세요.
팁을 드리자면, 연구자마다 title 을 적는 방식이 다르기 때문에, 여러 검색어로 해보시는게 좋습니다.
또 다른 팁은, 연구자들이 title에 넣었을 법한 간단한 단어 위주로 검색하셔야 해요.
난소암 환자의 RNA-seq 데이터 를 찾는다면 ovary, ovarian 등 몇몇 간단한 검색어를 활용하시면 좋아요.
ovarian 으로 한번 검색해 볼까요?
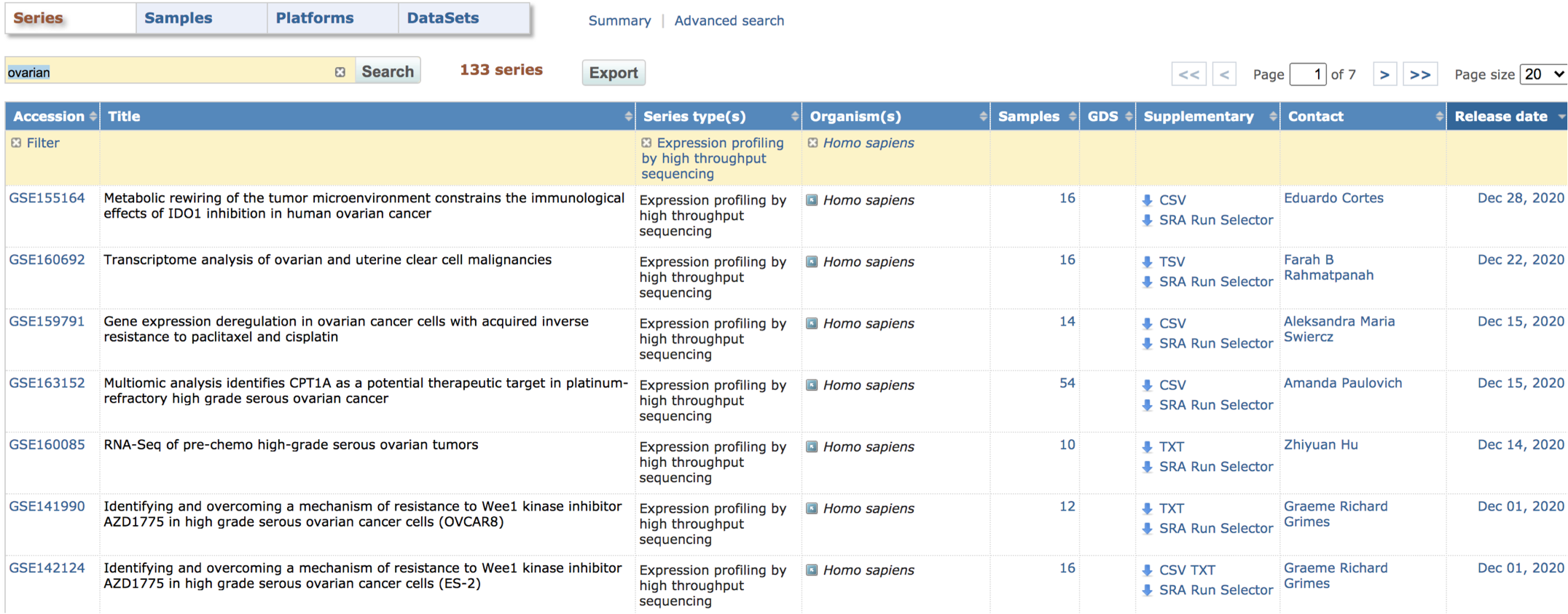 |
이제 133개 시리즈 데이터만 남았군요.
하지만 아직 끝이 아닙니다.
여러분들은 아마도 ‘적당한 수의 샘플이 있는’ 데이터를 찾고 싶을 수도 있고, ‘그나마 최신 데이터’ 를 원하실 수도 있어요.
이를 위해서는 표의 ‘정렬’ 기능을 활용하시면 됩니다.
표의 헤더 부분을 클릭하시면 오름차순, 내림차순 으로 정렬이 가능해요.
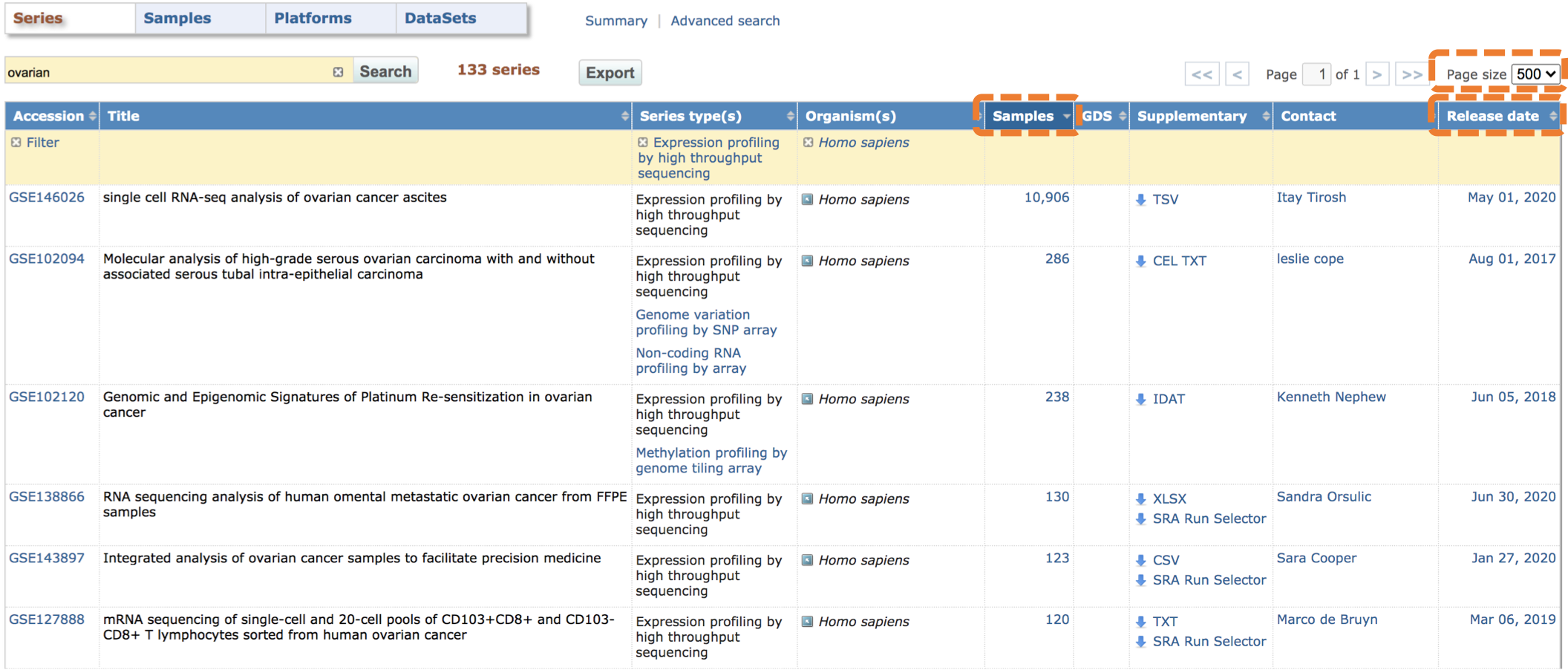
아, 참고로 오른쪽 위의 page size는 한 페이지에 보이는 시리즈 개수입니다.
최대 500개까지 가능하니 크게 크게 보세요 ^^
 |
|---|
| 저는 샘플 수 내림차순으로 정렬해 보았습니다. |
자, 이제 거의 다 왔습니다.
맨 위의 샘플 10,906개 짜리 데이터가 보이는군요.
보통 이렇게 샘플 수가 큰 경우는 single-cell RNA-seq 데이터인 경우입니다.
이를 분석 가능하신 분이라면 선택하시면 되겠습니다.
저희가 찾고자 하는 건 난소암 환자의 RNA-seq 데이터 이므로 이는 제외하구요.
이제 제목을 찬찬히 읽어보시면서 원하는 데이터인지 확인해보시고, 맞다면 series ID (GSE*****) 를 클릭하시면 됩니다.
팁을 한가지 더 드리자면, Supplementary 열을 잘 확인해보시는게 좋습니다.
만약 여러분께서 raw data (fastq) 부터 분석하려고 하신다면, 이는 SRA 데이터베이스에 저장되어 있으므로 ‘SRA Run Selector’ 로 필터해서 찾아보시면 됩니다.
그러나, 직접 분석하기는 좀 어렵고 이미 만들어져 있는 expression matrix 를 활용하실 분들은 ‘tsv’ 혹은 ‘txt’ 정보가 있는 시리즈만 선택해서 들어가셔야 합니다.
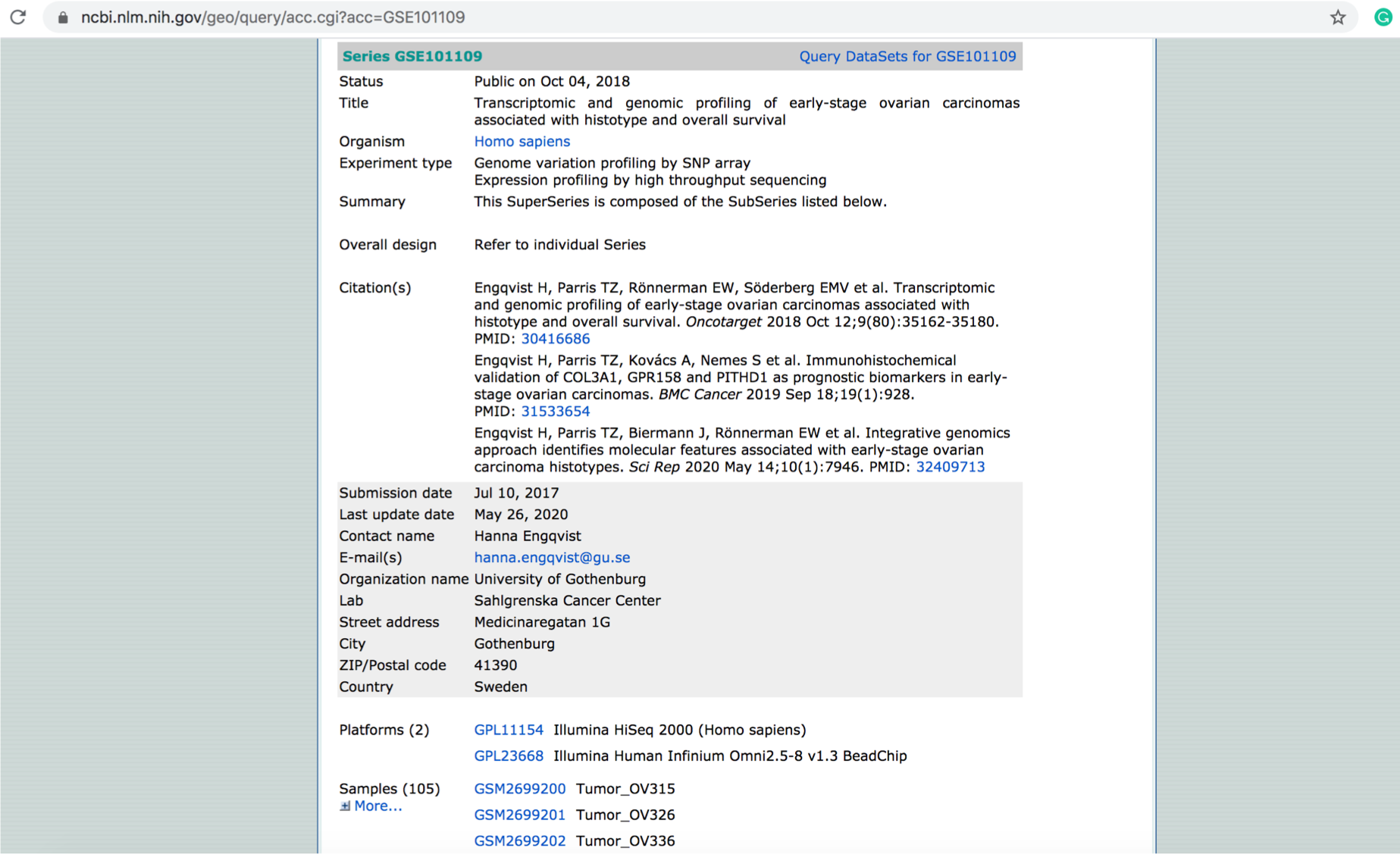 |
예시로 GSE101109 라는 시리즈를 들어가 보았습니다.
Early-stage ovarian cancer 데이터이고, overall survival data 까지 제공하는군요.
중간에 Experimental design 을 통해 실험이 어떻게 디자인 되었는지 확인할 수 있죠.
그리고 어떤 논문에서 쓰였는지도 나와있기 때문에, 이 논문을 참고하면 어떤 데이터인지 더 자세하게 들여다볼 수 있겠군요!
아래에는 사용된 플랫폼, 그리고 샘플들 정보가 나와있습니다. 샘플이 105개나 되는군요!
이렇게 시리즈의 정보를 읽어보며 여러분께서 찾고자 하는 데이터가 맞는지 확인해보시면 됩니다.
만약 아니라면, 아까 필터해놓은 여러 시리즈 중 다른 시리즈도 확인해보면 되겠죠.
네, 오늘은 GEO 에서 원하는 데이터를 찾아가는 과정을 설명해 보았습니다.
GEO는 전 세계에서 가장 많은 시퀀싱 데이터를 보유하고 있지만, 실제로 원하는 데이터를 찾는 것이 쉽지만은 않습니다.
여러분이 원하는 특정 디자인의 실험 데이터는 없는 경우가 다반사죠.
그래도 제가 설명한 방법을 통해 여러분의 연구에 도움되는 자료를 좀더 수월하게 찾아가시길 바랍니다.
다음에는 데이터를 실제로 활용하는 내용으로 찾아오겠습니다.
그럼 다음 시간에 만나요!